http://bestwhois.org/domain_name_data/domain_names_new
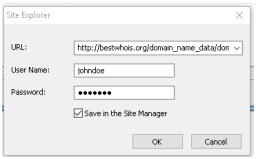
Also open the “Authenticate” part, enter your username and password, and check the “Save in the Site Manager” box:
Daily Domain Name Whois Updates Reference Manual (ccTLDs) Whois API Inc. |
The present documentation describes legacy products.
WhoisXML API, Inc. offers an improved service covering and extending the functionality of the here described ones.
For more information, visit
Please update your business processes on time.
This data feed subscription is licensed to you or your organization only, you may not resell or relicense the data without explicit written permission from Whois API LLC. Any violation will be prosecuted to the fullest extent of the law.
The present document is available in html, pdf and unicode text format from the following locations.
Primary URL:
Additional URLs:
File version 2.24.
Approved on 2023-09-13.
A full list of available WhoisXML API data feed manuals is available at
Our daily data feeds provide whois data for newly registered domains in both parsed and raw formats for download as database dumps (MySQL or MySQL dump) or CSV files.
In the following a detailed description is provided on the reasons of these timings and their possible fluctuations.
In order to understand when a newly registered domain will be visible in our WHOIS data feeds or through our API it is necessary to understand how WHOIS data are generated and get to our subscribers:
As a consequence, even under normal circumstances there is 12-36-hour real delay between the date in the WHOIS record and its availability in our database. Looking at the dates only, it can seemingly result in up to 3 days of delay, which might even be more if the date is not interpreted together with time in the appropriate time zone for some reason.
In addition to the regular delays mentioned above, there might be additional reasons of the delay occurring occasionally. Some examples:
An approximate schedule is provided in the detailed description of each feed. Note, however, that the downloading and preprocessing of data is a compute-intensive task, hence, the schedule has to be considered as approximate. As a rule of thumb: csv files are prepared mostly on time while WHOIS data and mysql dumps, whose preparation time depends on external resources and require more runtime, has usually more delay and the preparation time may have a significant variance compared to the schedule given below.
We provide an opportunity to precisely verify if certain files are already prepared and ready to be downloaded, both in the form of an RSS feed and other methods. This is described in Section 2.5.
By a “supported top-level domain (TLD)” it is meant that obtaining WHOIS data is addressed by the data collection procedure, and thus there are WHOIS data provided. (In some cases bigger second-level domains (SLDs) are treated separately from their TLDs in the data sources as if they were separete TLDs, hence, we refer to these also as “TLDs” in what follows.) The set of supported TLDs can vary in time, thus it is specified for each quarterly database version or day in case of quarterly and daily data sources, respectively. See the detailed documentation of the data feeds on how to find the respective list.
If a TLD is unsupported, it means that the given data source does not contain WHOIS data for the given TLD. There are many for reasons for which a domain is unsupported by our data sources; typically the reason behind is that it does not have a WHOIS server or any other source of WHOIS data or it is not available for replication for technical or legal reasons. A list of TLDs domains which are constantly unsupported by all feeds is to be found at
For these domains we provide a file limited information that include just name server info in certain data sources; notably in quarterly feeds.
As of the list of supported TLDs, these are listed in auxiliary files for each data source separately. See the documentation of the auxiliary files for details.
Many of the data feeds contain information about changes, such as “newly registered domains”. It is important to note that the change is detected by us via the analysis of the respective zone files: a domain appears in a daily feed of this type if there has been a change in the respective zone file, for instance, it has appeared and was not there directly before.
For this reason there might be a contradiction between the appearance of the domain as a newly registered one and the date appearing in the “createdDate” field of the actual WHOIS record. It occurs relatively frequently that the domain name disappears from the zone file, then appeared again. (Sometimes some domains are even not in the zone file and when we check by issuing a DNS request the domain is actually found by the name server.)
To illustrate this issue: given a domain with
Updated Date: 2018-04-23T07:00:00Z Creation Date: 2015-03-09T07:00:00Z
may appear on 2018-04-23 as a newly registered one. And, unfortunately, sometimes the “updated date” in the WHOIS record is also inaccurate, and therefore the domain appears as new in contrast to any data content of the WHOIS record.
Looking closer at the reasons why a domain disappears temporarily from the zone file (and therefore it gets detected as new by us upon its reappearance), one finds that the typical reason is due to certain domain status values. Namely, a domain name is not listed in zone-file if it is in either of the following statuses:
Server-Hold Client-Hold PendingDelete RedemptionPeriod
For instance, if a domain that has expired and gone into the redemptionPeriod, it will not show in the zone file, but if the current owner redeems it the next day, it will reappear. A A registrar may also deem that a domain has violated their terms of service and put them on clientHold until they comply. This removes the domain at least temporarily from the zone file as well.
As a rule of thumb, if you really want to decide whether a domain which has just appeared in the zone file (and thus is included into our respective feeds) was a newly registered on a given day, please add a check of the contents of the “createdDate” field in the course of processing the data.
The discrepancies in other feeds related to changes, e.g. with data of dropped domains can be understood along the same lines.
For a more detailed explanation about this, see also Section 9.
Important note: The directories discussed in this section may contain subdirectories and/or files not described here. These are temporary, they are there for technical reasons only. Please ignore them.
Newly registered domains for ccTLDs.
URL:
Important note on the schedule: the data for this feed are generated in two phases, whose completion time differs. The data for a part of the TLDs concludes typically on the given date, whereas the data for fr,re,pm,tf,wf,yt appear about one day later. Hence, the status directory has files
indicating that the data for all but the above domains are complete, whereas the presence of the
indicates the ultimate completion. The partial completion is also reflected in the rss notifications.
Newly dropped domains for ccTLDs
URL:
Whois data for nelwy registered domains for ccTLDs.
URL:
Whois data for nelwy dropped domains for ccTLDs.
Note: in case of some of the ccTLDs the whois information becomes unavailable very shortly after the act of dropping the domain. Hence, it is possible that in this feed there are data for much less domains than in the feed cctld_registered_domain_names_dropped, and this is normal.
URL:
Newly discovered domains for ccTLDs. These are newly discovered domains
from our world-wide third party DNS sensors (some of which tend to be newly registered). See also Section 10.
URL:
ccTLDs and gTLDs in the daily_tlds subdirectory listed in the .tlds files in a single line, separated by commas.
Whois data for newly discovered domains for ccTLDs. These are newly discovered domains
from our world-wide third party DNS sensors (some of which tend to be newly registered). See also Section 10.
The data are available here for 65 days. The files older than 65 days are moved to the feed
cctld_discovered_domain_names_whois_archive
URL:
Historic data from the data feed cctld_discovered_domain_names_whois.
URL:
in the subdirectory of the feeds, e.g.
contain information on tlds supported on a particular day. Similarly, the files
contain a list of those tlds which have new data on a particular day.
All data formats are identical.
Important note: the time information seen on the web server in the file listings is always to be understood in GMT/UTC. Users who do automated processing with scripts should note that when downloaded with the wget utility to a local file, this file is saved under the same datetime as it was found on the server, but it appears locally according to the local user’s locale settings.
For example, a file seen on a subdirectory of bestwhois.org displayed in the listing having a time 21:30, this is GMT. However, for instance, in Central European Summer Time (CEST) it is 23:30, so if you reside in this latter timezone and your computer is set accordingly, this will appear in the local file listing.
Each feed subdirectory contains a status subdirectory, e.g. the feed domain_names_whois has
Within the status directory each daily non-archive feed has a file named download_ready_rss.xml, which is an RSS feed providing immediate information if the data in the feed in a given format are finalized and ready for downloading. For instance, if the regular csv data of the above mentioned domain_names_whois feed are ready for downloading, the in RSS feed
the following entry will appear:
{"data_feed": "cctld_registered_domain_names_whois",
"format": "regular_csv",
"day": "2021-08-24",
"available_from": "2021-08-25 18:09:52 UTC"}
indicating that the regular csv data of the cctld_registered_domain_names_whois feed for the day 2021-01-30 are ready for downloading from 2021-01-30 23:05:42 UTC. The entry is in JSON format so it is suitable for a machine-based processing: the maybe most efficient way to download complete data as soon as they are available is to observe this feed and initiate the download process as soon as the RSS entry appears. (Premature downloading on the other hand can produce incomplete data.)
As another indication of the readiness of a given data set, the status subdirectories in each feed’s directory contain files which indicate the actual completion time of the preparation of the data files described in Section 1.2. These can be used to verify if a file to be downloaded according to the schedule is really complete and ready to be downloaded. Namely, if a file
yyyy_MM_dd_download_ready_csv
exists in the status subdirectory then the generation of
yyyy_MM_dd_$tld.csv.gz
has been completed completed by the time of the creation datetime of the file
yyyy_MM_dd_download_ready_csv
and it is ready to be downloaded since. The contents of yyyy_MM_dd_download_ready_csv are irrelevant, only their existence and creation datetime are informative. Similarly, the files
yyyy_MM_dd_download_ready_csv
correspond to the data files
yyyy_MM_dd_$tld.csv.gz
while the
yyyy_MM_dd_download_ready_mysql
correspond to the
add_mysql_yyyy_MM_dd_$tld.csv.gz
data files.
The text files
in the status subdirectories, wherever they exist, provide information about the filename, file size and modification time for each of the relevant data files. This file is updated whenever a file is regenerated.
Each feed subdirectory contains a
subdirectory, e.g. the feed domain_names_whois contains
These subdirectories contain contain md5 and sha hashes of the downloadable data files accessible from their parent directories. These can be used to check the integrity of downloaded files.
CSV files (Comma-Separated Values) are text files whose lines are records whose fields are separated by the field separator character. Our CSV files use Unicode encoding. The line terminators may vary: some files have DOS-style CR+LF terminators, while some have Unix-style LF-s. It is recommended to check the actual file’s format before use. The field separator character is a comma (“,”), and the contents of the text fields are between quotation mark characters.
CSV-s are very portable. They can also be viewed directly. In Section 8 you can find information on software tools to view the contents and handle large csv files on various platforms.
In Section 6 we describe client-side scripts provided for end-users. The available scripts include those which can load csv files into MySQL databases. In particular, a typical usecase is to load data from CSV files daily with the purpose of updating an already existing MySQL WHOIS database. This can be also accomplished with our scripts.
CSV files can be loaded into virtually any kind of SQL or noSQL database, including PostgreSQL, Firebird, Oracle, MongoDB, or Solr, etc. Some examples are presented in the technical blog available at
There are 2 types of CSVs and 1 type of Database dump for whois records.
"domainName", "registrarName", "contactEmail", "whoisServer",
"nameServers", "createdDate", "updatedDate", "expiresDate",
"standardRegCreatedDate", "standardRegUpdatedDate",
"standardRegExpiresDate", "status", "RegistryData_rawText",
"WhoisRecord_rawText", "Audit_auditUpdatedDate", "registrant_rawText",
"registrant_email", "registrant_name", "registrant_organization",
"registrant_street1", "registrant_street2", "registrant_street3",
"registrant_street4", "registrant_city", "registrant_state",
"registrant_postalCode", "registrant_country", "registrant_fax",
"registrant_faxExt", "registrant_telephone", "registrant_telephoneExt",
"administrativeContact_rawText", "administrativeContact_email",
"administrativeContact_name", "administrativeContact_organization",
"administrativeContact_street1", "administrativeContact_street2",
"administrativeContact_street3", "administrativeContact_street4",
"administrativeContact_city", "administrativeContact_state",
"administrativeContact_postalCode", "administrativeContact_country",
"administrativeContact_fax", "administrativeContact_faxExt",
"administrativeContact_telephone", "administrativeContact_telephoneExt",
"billingContact_rawText", "billingContact_email", "billingContact_name",
"billingContact_organization", "billingContact_street1",
"billingContact_street2", "billingContact_street3",
"billingContact_street4", "billingContact_city", "billingContact_state",
"billingContact_postalCode", "billingContact_country",
"billingContact_fax", "billingContact_faxExt",
"billingContact_telephone", "billingContact_telephoneExt",
"technicalContact_rawText", "technicalContact_email",
"technicalContact_name", "technicalContact_organization",
"technicalContact_street1", "technicalContact_street2",
"technicalContact_street3", "technicalContact_street4",
"technicalContact_city", "technicalContact_state",
"technicalContact_postalCode", "technicalContact_country",
"technicalContact_fax", "technicalContact_faxExt",
"technicalContact_telephone", "technicalContact_telephoneExt",
"zoneContact_rawText", "zoneContact_email", "zoneContact_name",
"zoneContact_organization", "zoneContact_street1", "zoneContact_street2",
"zoneContact_street3", "zoneContact_street4", "zoneContact_city",
"zoneContact_state", "zoneContact_postalCode", "zoneContact_country",
"zoneContact_fax", "zoneContact_faxExt", "zoneContact_telephone",
"zoneContact_telephoneExt", "registrarIANAID"
"domainName", "registrarName", "contactEmail", "whoisServer",
"nameServers", "createdDate", "updatedDate", "expiresDate",
"standardRegCreatedDate", "standardRegUpdatedDate",
"standardRegExpiresDate", "status", "RegistryData_rawText",
"WhoisRecord_rawText", "Audit_auditUpdatedDate", "registrant_rawText",
"registrant_email", "registrant_name", "registrant_organization",
"registrant_street1", "registrant_street2", "registrant_street3",
"registrant_street4", "registrant_city", "registrant_state",
"registrant_postalCode", "registrant_country", "registrant_fax",
"registrant_faxExt", "registrant_telephone", "registrant_telephoneExt",
"administrativeContact_rawText", "administrativeContact_email",
"administrativeContact_name", "administrativeContact_organization",
"administrativeContact_street1", "administrativeContact_street2",
"administrativeContact_street3", "administrativeContact_street4",
"administrativeContact_city", "administrativeContact_state",
"administrativeContact_postalCode", "administrativeContact_country",
"administrativeContact_fax", "administrativeContact_faxExt",
"administrativeContact_telephone", "administrativeContact_telephoneExt",
"billingContact_rawText", "billingContact_email", "billingContact_name",
"billingContact_organization", "billingContact_street1",
"billingContact_street2", "billingContact_street3",
"billingContact_street4", "billingContact_city", "billingContact_state",
"billingContact_postalCode", "billingContact_country",
"billingContact_fax", "billingContact_faxExt",
"billingContact_telephone", "billingContact_telephoneExt",
"technicalContact_rawText", "technicalContact_email",
"technicalContact_name", "technicalContact_organization",
"technicalContact_street1", "technicalContact_street2",
"technicalContact_street3", "technicalContact_street4",
"technicalContact_city", "technicalContact_state",
"technicalContact_postalCode", "technicalContact_country",
"technicalContact_fax", "technicalContact_faxExt",
"technicalContact_telephone", "technicalContact_telephoneExt",
"zoneContact_rawText", "zoneContact_email", "zoneContact_name",
"zoneContact_organization", "zoneContact_street1", "zoneContact_street2",
"zoneContact_street3", "zoneContact_street4", "zoneContact_city",
"zoneContact_state", "zoneContact_postalCode", "zoneContact_country",
"zoneContact_fax", "zoneContact_faxExt", "zoneContact_telephone",
"zoneContact_telephoneExt", "registrarIANAID"
The csv data fields are mostly self-explanatory by name except for the following:
domainName: 256, registrarName: 512, contactEmail: 256, whoisServer: 512, nameServers: 256, createdDate: 200, updatedDate: 200, expiresDate: 200, standardRegCreatedDate: 200, standardRegUpdatedDate: 200, standardRegExpiresDate: 200, status: 65535, Audit_auditUpdatedDate: 19, registrant_email: 256, registrant_name: 256, registrant_organization: 256, registrant_street1: 256, registrant_street2: 256, registrant_street3: 256, registrant_street4: 256, registrant_city: 64, registrant_state: 256, registrant_postalCode: 45, registrant_country: 45, registrant_fax: 45, registrant_faxExt: 45, registrant_telephone: 45, registrant_telephoneExt: 45, administrativeContact_email: 256, administrativeContact_name: 256, administrativeContact_organization: 256, administrativeContact_street1: 256, administrativeContact_street2: 256, administrativeContact_street3: 256, administrativeContact_street4: 256, administrativeContact_city: 64, administrativeContact_state: 256, administrativeContact_postalCode: 45, administrativeContact_country: 45, administrativeContact_fax: 45, administrativeContact_faxExt: 45, administrativeContact_telephone: 45, administrativeContact_telephoneExt: 45, registarIANAID: 65535
The [contact]_country fields are standardized. The possible values are listed in the first column of the file
The possible country names are in the first column of this file; the field separator character is “|”.
Even though CSV is an extremely portable format accepted by virtually any system, in many applications, including various NoSQL solutions as well as custom solutions to analyze WHOIS data, the JSON format is preferred.
The data files which can be downloaded from WhoisXML API can be converted to JSON very simply. We provide Python scripts which can be used to turn the downloaded CSV WHOIS data into JSON files. These are available in our Github repository under
We refer to the documentation of the scripts for details.
Using mysqldump is a portable way to import the database.
This is equivalent to running the following in mysql
mysql -uroot -ppassword -e "create database whoiscrawler_com"
zcat add_mysqldump_2015_01_12_com.sql.gz | \
mysql -uroot -ppassword whoiscrawler_com --force
There are 3 important tables in the database:
in some database dump files, especially dailies, the maximum size of the VARCHAR and BIGINT files is smaller than what is described in the above schema. When using such database dumps together with others, it is recommended to set the respective field length to the “failsafe” values, accodding to the here documented schema. For instance, in case of daily WHOIS database dump from the domain_names_whois data feed, the recommended modifications of the maximum lengths of VARCHAR or BIGINT fields are:
There can be many approaches for creating and maintaining a MySQL domain WHOIS database depending on the goal. In some cases the task is cumbersome as we are dealing with big data. Our client-slide scripts are provied as samples to help our clients to set up a suitable solution; they can be used as they are in many cases. All of them come with a detailed documentation.
Some of our blogs can be also good reads with this respect, for instance, this one:
Scripts are provided in support of downloading WHOIS data through web-access and maintaining a WHOIS database. These are available on github:
The actual version can be downloaded as a zip package or obtained via git or svn.
There are scripts in Bourne Again Shell (BASH) as well as in Python (natively supported also on Windows systems).
The subdirectories of the repository have the following contents:
In addition, the scripts can be used as a programming template for developing custom solutions. The script package includes a detailed documentation.
In this Section we provide additional information in support of web-downloading the feeds. This includes recommendations about organizing and scheduling the download process as well as some tips for those who want to download multiple files from the data feeds via web access by either using generic software tools, either command-line based or GUI for some reason. We remark, however, that our downloader scripts are at our clients’ disposal, see Section 6 on their details. Our scripts provide a specialized solution for this task, and the Python version can be run in GUI mode, too.
Note: this information describes both the case of quarterly releases and daily data feeds, as most users who do this process will use both.
While the data feeds’ web directories are suitable for downloading a few files interactively, in most cases the download is to be carried out with an automated process. To implement this,
The organization of the web directories is described at each data feed in the present manual. Given a day (e.g. 2020-03-15) or database release (e.g. v31), a TLD name (e.g. .com), the URL of the desired files can be put together easily after going through the data feed’s docs. E.g. the regular csv data for .com in the v31 quarterly release will be at
http://www.domainwhoisdatabase.com/whois_database/v31/csv/tlds/regular
whereas the daily data for 2020-03-15 of this domain will be at
http://bestwhois.org/domain_name_data/domain_names_whois/2020_03_15_com.csv.gz
The downloader scripts supplied with our products (c.f. Section 6) given the feed’s name and the data format’s name. But what should be the TLD name.
The broadest list a data feed can have data for is that of the supported TLDs, consult Section 2.1 for the explanation. Their actual list depends on the database release in case of quarterlies, and on the data feed and day in case of daily feeds. To use an accurate list, check the auxiliary files provided to support download automation. In particular, the list will be in the subdirectory
If a domain is supported, it is not necessary that it has data in all the daily feeds. E.g. if there were no domains added on a day in a give TLD, it will not have data files on a given day. Hence, the lack of a file for a given supported TLD on a given day can be normal.
Another option in case of daily feeds is to use another supplemental file provided with the data feed. E.g. in case of domain_names_new, the files
status/added_tlds_YYYY_MM_DD
will give a list of domains for which there are actual data on the given day.
The key question is: when a set of files are ready for downloading. In case of quarterly releases the availability is announced via e-mail to subscribers, and so are possible extensions or corrections.
In case of daily data the tentative schedule information is published here:
As the actual availability times vary, there are supplemental files (typically named status/*download_ready*, consult the description of the feeds) whose existence indicates that the data are ready for downloading, and their file date reflects the time when they became available.
If a given data file was unavailable when a scheduled attempt was made, it has to be downloaded again. For most files we provide md5 and sha256 checksum files, see the detailed docs of the data feeds for their naming convention.
When attempting to redownload a file, a recommended method is to download its checksum. If there is an already downloaded version of the file which is inline with the checksum, no redownload is needed. If the check fails, or the file is not there, the file has to be redownloaded. This policy is implemented by the Python downloader provided with the products, which is also capable of continuing a broken download. The downloader script in BASH will repeat downloading if and only if the file is absent.
Implementing this policy, or using the provided scripts, a recommended approach is to repeat the download procedure multiple times, going back a few days, and keep the downloaded files in place. Thereby all the missing files will get downloaded, and the ones which are downloaded and are the same as the one on the web server will be skipped.
GUI-based downloading is mainly an option for those who download data occasionally as it less efficient than the command-line approach and cannot be automated. Primarily we recommend to use or python downloader (Section 6) which comes with a simple GUI specialized for downloading from our data feeds.
There are, however, several stand-alone programs as well as browser plugins intended for downloading several files at once from webpages. Unfortunately, however, most of these are not very suitable for the purpose of downloading from WhoisXML API feeds. There are some exceptions, though. In the following we describe one of them, iGetter, which we found suitable for the purpose.
The program is available for Mac and Windows. It is a Shareware and can be downloaded from
http://www.igetter.net/downloads.html
After downloading it, simply follow the installation instructions.
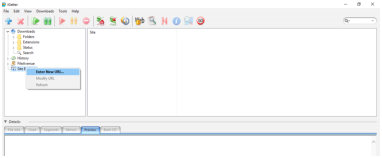
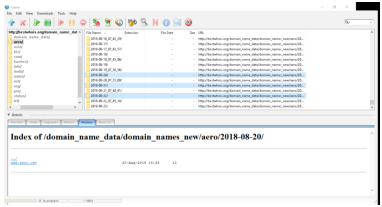
In the following description, the screenshots come from a Windows 10 system, under Mac OS X, the process is similar. The task is to download 3 days of data of the TLDs “aero” and “biz” from the feed “domain_names_new”. The dates will be from 2018.08.20 to 2018.08.22. (It is an example with a daily feed, but in case of quarterly feeds the process is very similar, as it is essentially about downloading a set of files from a web-hosted directory structure.) It can be carried out as follows:
http://bestwhois.org/domain_name_data/domain_names_new
Also open the “Authenticate” part, enter your username and password, and check the “Save in the Site Manager” box:
For further tips and tweaks, consult the documentation of the software.
There are various command-line tools for downloading files or directories from web-pages. They provide an efficient way of downloading and can be used in scripts or batch files for automated downloading.
Most of these are available freely in some form on virtually any platform. These are, e.g. curl, pavuk, or https://www.gnu.org/software/wgetwget, to mention the maybe most popular ones. Here we describe the use of wget through some examples as this is the maybe most prevalent and it is very suitable for the purpose. We describe here a typical example of its use. Those who plan to write custom downloader scripts may take a look a the BASH downloader script we provide: it is also wget-based. We refer to its documentation for further details or tweaks.
To install wget you can typically use the package management of your system. For instance, on Debian-flavor Linux systems (including the Linux subsystem available on Windows 10 platforms) you can install it by the command-line
udo apt-get install wget A native Windows binary is available from
http://gnuwin32.sourceforge.net/packages/wget.htm
The program expects an URL as a positional argument and will replicate it into the directory where it is invoked from. The following options are the maybe most relevant for us:
In the present example we shall download data of the “aero” TLD from the feed “domain_names_new” for 2018-08-20. (It is an example with a daily feed, but similar examples can be easily constructed also for quarterly feeds. In general it is about downloading a file replicating the directory structure of the web server.)
wget -r -l1 --user=johndoe --password=johndoespassword
"http://bestwhois.org/domain_name_data/domain_names_new/aero/2018-08-20/add.aero.csv"
This will leave us with a directory structure in the current working directory which is a replica of the one at the web server:
. |-bestwhois.org |---domain_name_data |-----domain_names_new |-------aero |---------2018-08-20 |-----------add.aero.csv
Noe that we could have downloaded just the single file:
wget --user=johndoe --password=johndoespassword \
"http://bestwhois.org/domain_name_data/domain_names_new/aero/2018-08-20/add.aero.csv"
but this would leave us with a single file “add.aero.csv” which is hard to identify later. Albeit wget is capable of downloading entire directories recursively, the good strategy is to collect all the URLs of single files to get and download them with a single command-line each. This can be automated with script or batch files. Consult the BASH downloader script provided for downloading to get additional ideas, and the documentation of wget for more tweaks.
In this Section we describe some possible ways how to view or edit large csv files on various operating systems.
CSV files are plain text files by nature. Their character encoding is UTF8 Unicode, but even UTF8 files can have three different formats which differ in the line terminator characters:
as the terminator character of lines. While the third option is obsolete, the first two types of files are both prevalent.
The files provided by WhoisXML API are generated with different collection mechanisms, and for historic reasons both formats can occur. Even if they were uniform with this respect, some download mechanisms can include automatic conversion, e.g. if you download them with FTP, some clients convert them to your system’s default format. While most software, including the scripts provided by us handle both of these formats properly, in some applications it is relevant to have them in a uniform format. In what follows we give some hint on how to determine the format of a file and convert between formats.
To determine the line terminator the easiest is to use the “file” utility in your shell (e.g. BASH, also available on Windows 10 after installing BASH on Ubuntu on Windows): for a DOS file, e.g. “foo.txt” we have (“$” stands for the shell prompt):
$ file foo.csv foo.txt: UTF-8 Unicode text, with CRLF line terminators
whereas if “foo.txt” is Unix-terminated, we get
$ file foo.csv foo.txt: UTF-8 Unicode text
or something alike, the relevant difference is whether “with CRLF line terminators” is included.
To convert between the formats, the command-line utilities “todos” and “fromdos” can be used. E.g.
$ todos foo.txt
will turn “foo.txt” into a Windows-style CR + LF terminated file (regardless of the original format of “foo.txt”), whereas using “fromdos” will do the opposite. The utilities are also capable of using STDIN and STDOUT, see their manuals.
These utilities are not always installed by default, e.g. on Ubuntu you need to install the package “tofrodos”. Formerly the relevant utilities were called “unix2dos” and “dos2unix”, you may find them under this name on legacy systems. These are also available for DOS and Windows platforms from
In Windows PowerShell you can use the commands “GetContent” and “SetContent” for the purpose, please consult their documentation.
You can use an advanced editor that support handling large files, such as
You can split a CSV file into smaller ones with CSV Splitter
(http://erdconcepts.com/dbtoolbox.html).

You may import csv files into the spreadsheet application of your favorite office suite, such as Excel or LibreOffice Calc.
Note: If you want to use MS Excel, it would be advisable to use a newer version of Excel like 2010, 2013 and 2016.
On Windows, you can also use the bash shell (or other UNIX-style shells) which enables several powerful operations on csv files, as we describe here in Section 8.4 of this document.
In order to do so,
Having installed the appropriate solution, you can handle your csv-s also as described in Section 8.4.
You can use one of the advanced text editors such as:
You may import csv files into the spreadsheet application of your favorite office suite, such as Excel or LibreOffice Calc.
Note: If you want to use MS Excel, it would be advisable to use a newer version of Excel like 2010, 2013 and 2016.
Open a terminal and follow Subsection 8.4
You can split csv files into smaller pieces by using the shell command split, e. g.
split -l 2000 sa.csv
shall split sa.csv into files containing 2000 lines each (the last one maybe less). The “chunks” of the files will be named as xaa, xab, etc. To rename them you may do (in bash)
for i in x??; do mv "$i" "$i.csv"; done
so that you have xaa.csv, xab.csv, etc.
The split command is described in detail in its man-page or here:
We also recommend awk, especially GNU awk, which is a very powerful tool for many purposes, including the conversion and filtering csv files. It is available by default in most UNIX-style systems or subsystems. To get started, you may consult its manual:
In this Section we describe how we describe in detail how and on which day a domain gets listed in a certain daily data feeds, that is, how the process behind the feeds detect the Internet domains have been registered, dropped or modified on a given day.
In principle, WHOIS records contain date fields that reflect the creation, modification, and deletion dates. It is not possible, however, to search the WHOIS system for such dates. In addition, there can be a delay between the actual date and the appearance of the WHOIS record: the presence of WHOIS information is not required by the technical operation of a domain, so registrars and registries are not very strict with updating the WHOIS system. Hence, it is not possible to efficiently obtain daily updates of WHOIS data entirely from the WHOIS system itself.
Most of the daily feeds thus follow another strategy. The technical operation of a domain requires its presence in the Domain Name System (DNS). So a domain starts operating if it appears in the zone file of the domain, and ceases to operate when it disappears from it. We refer to our white paper on DNS:
for further details. As for modifications of domains, the approach of the “delta” feeds’ data generation is to look for domains which have changed either of their name servers in the zone file: most of the relevant changes in a domain, like the change in the ownership imply such a change. In the following subsections we explain how the date when the domain appears in a daily feed is related to the one in its WHOIS record, and assess the accuracy of the data feeds.
Domains have their life cycle. For domains GTLDs this is well-defined, while in case of those in ccTLDs it can depend on the authoritative operator of the given TLD. So as a reference, in case of domains in a generic top-level domain, such as .com the life cycle can be illustrated illustrated in the following figure:
Notice that in the auto-renew grace period, which can be *0-45* days, the domain may be in the zone file, so it may actively operate or not.
The deadline of introducing or removing the WHOIS record can vary, there is no very strict regulation of this. So it easily happens that the domain already works but has no WHOIS record yet, or the other way around: the domain does not work, it is not in the zone file, but it already (or still) has a WHOIS record.
Because of the nature of the described life cycle, the day of the appearance of a domain in a feed of new, modified or dropped domains (i.e. the day in the file name) is not exactly the day in the WHOIS record corresponding to the given event. In the daily feed there are the domains which start to technically function on that day, maybe not the first time even. (It might also happen that an entry in the zone file changes just because some error.) The date in the WHOIS record is, on the other hand the date when the domain was officially registered, but it is not forced to coincide with the time when it started to function.
The number of the record in the daily data feed, however, will show the same or similar main trends even if it will not coincide with the number of domains found with the given date in the WHOIS database, which can be found out later, via querying a complete database. But the maintenance of a complete database is definitely more resource expensive than counting the number of lines of some files, so it is a viable approach to study domain registration, modification, or deletion trends.
In relation to accuracy, a frequent misunderstanding is the notion of “today”. When talking about times, one should never forget about time zones. A date in the WHOIS record having a date for yesterday can be today in another time zone.
Another systematic feature of our methodology is that the WHOIS records for domains with status codes indication that in they are in the redemption grace period or pending delete period are not all captured. It is for the reason that if we detect that a domain is disappearing from the zone file it can have two meanings: it is somewhere in its auto-renew grace period or it has just started its redemption grace period. The uncertainty is because in the auto-renew grace period, "the domain may be in the zone file". And it is very likely that it is just the status which changes when it disappears from the zone file, so we will probably not have too much new information from the rest of these records.
As mentioned in Section , the data collection based on changes in DNS zone files is not always feasible in case of ccTLDs as the DNS zone files are not available. Hence, to provide data for maintaining an up-to-date WHOIS database, different approaches are required. We use various third-party DNS sensors as well as a web crawler to collect domain names under ccTLDs. The data feeds cctld_discovered_domain_names_new and cctld_discovered_domain_names_whois data feeds contain data from these sources.
Unfortunately these collection methods rely on network traffic or actual information on the World Wide Web, hence, the date of the data feed files are not related to the dates in the WHOIS record of the feed. The date just refers to the day when the domain was detected. This methodology is suitable for finding domains not seen before, but WHOIS record changes and dropped domains cannot be detetcted this way. The feed is cumulative in the sense that a domain detected recently is not repeated in the daily files if detected again.
Unfortunately, in case of many ccTLDs there is no other information available. Nevertheless, the two feeds, containing domains that have been detected by us on a given day and the respective WHOIS data are still useful for maintaining an up-to-date WHOIS database.
As WHOIS data come from very diverse sources with different policies and practices, their quality vary by nature. The data accuracy is strongly effected by data protection regulations, notably the GDPR of the European Union. Thus the question frequently arises: how to check the quality of a WHOIS record. In general, an assessment can be done in based on the following principles.
To decide if a record is acceptable at all, we recommend to check the following aspects:
If these criteria are met, the record can be considered as valid in principle. Yet its quality is still in a broad range. To further assess the quality, the typical approaches
In what follows we describe how to check these aspects in case of the different download formats.
In case of csv files the file has to be read and parsed. Then the empty or redacted fields can be identified, while the non-empty fields can possibly be validated against the respective criteria.
The WHOIS databases recovered from MySQL dumps contain a field named “parseCode”, which makes the quality check more efficient. (It is not present in the csv files.) It is a bit mask indicating which fields have been parsed in the record; a binary value of 1 at position i points to a non-empty value field at that position.
The fields from the least significant bit to the most significant one are following: "createdDate", "expiresDate", "referralURL" (exists in "registryData" only), "registrarName", "status", "updatedDate", "whoisServer" (exists in "registryData" only), "nameServers", "administrativeContact", "billingContact", "registrant", "technicalContact", and "zoneContact". For example, a parse code 310=(112) means that the only non-empty fields are "createdDate" and "expiresDate", whereas the parse code 810=(10002) means that the only non-empty field is "registrarName".
If you need to ascertain that a WHOIS record contains ownership information, calculate the binary AND of the parse code and 00100000000002=51210 it should be 512. (The mask stands for the non-empty field “registrant”).
We support SSL Certificate Authentication as an alternative to the plain login/password authentication when accessing some of our data feeds on the Web. This provides an encrypted communication between the client’s browser and the server when authenticating and downloading data. Here we describe how you can set up this kind of authentication.
In order to use this authentication, you as a client will need a personalized file provided to you by WhoisXML API, named pack.p12. This is a password-protected package file in PKCS12 format which can be easily installed on most systems. We typically send the package via e-mail and the respective password separately in an SMS message for security reasons. The package contains everything neceassary for the authentication:
Assuming that you have obtained the package and the respective password, in what follows we describe how to install it on various platforms.
Double click on the pack.p12 file. The following dialog windows will appear, you can proceed with "Next":
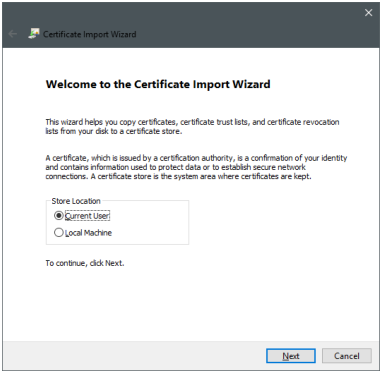
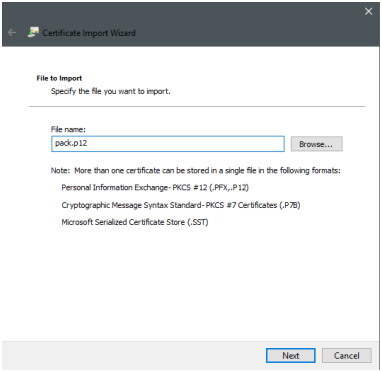
In the next step you should provide the password you got for the package. Then you can just go through the next dialogs with the default settings:
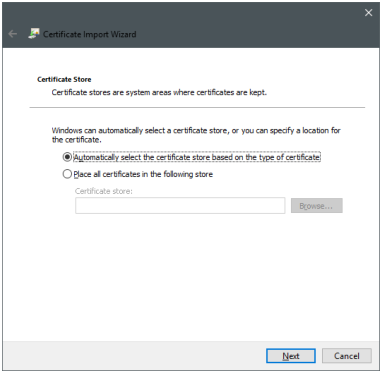
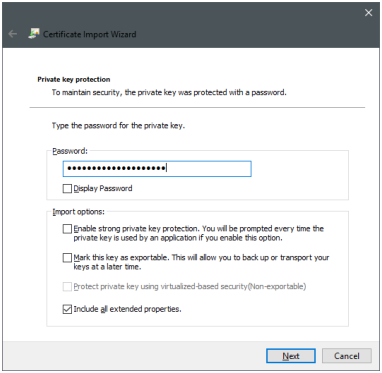
You can safely answer "Yes" to the following warning. It just says that you trust our CA server.

Your installation is complete now. You can verify or revise this or any of your certificates anytime with the certmgr.msc tool:
You should see the root certificate:
and your personal certificate

And as the main implication, after confirming the certificate you can open now the URLs you are eligible for, listed in Section 12.2, securely and without being prompted for passwords:

Double click the file pack.p12. The system will prompt for the password of the package, type it in, and press OK):
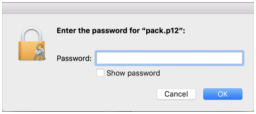
Note: you cannot paste the password into this latter dialog, so you need to type it. The Keychain Access tool window will open after the import:
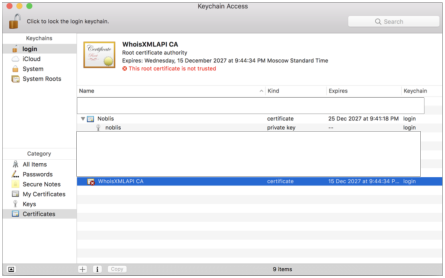
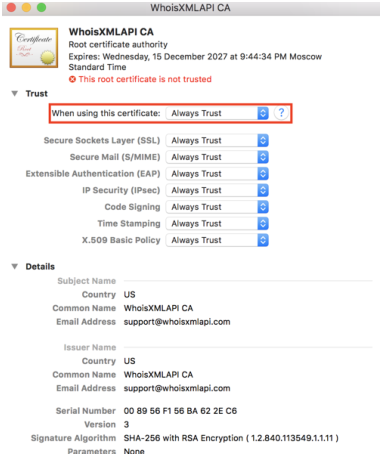
WhoisXMLAPI certificate is not trusted by default, so double click on WhoisXMLAPI ca certificate. Choose "Always Trust" from the dropdown menu and close the window. The Administrator password is required to apply this setting. Afterwards, our root certificate should appear as trusted:

If you start the Safari web-browser and open any of the URLs listed in Section 12.2, it will ask for certificate to be used for authentication: and the username-password pair to access the keychain:

Then the requested page will open securely and without the basic http authentication.
On Linux systems the procedure is browser dependent. Some browsers (e.g. Opera) use the standard database of the system, while others, such as Firefox, use their own certificate system. We show briefly how to handle both cases.
Go to Edit → Preferences in the menu. Choose the "Privacy/Security" tab on the left. You should see the following:
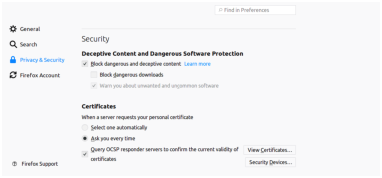
Press "View Certificates" and choose the "Your Certificates" tab. The certificate manager will appear:
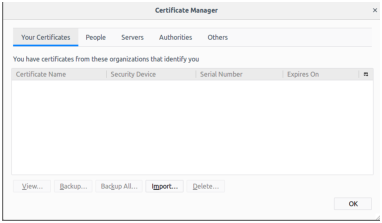
Press "Import", choose the file "package.p12", and enter the password you were given along with the certificate. You should see the certificate in the list. Now open any of the accessible URLs. You shall be warned as the browser considers the page as insecure:
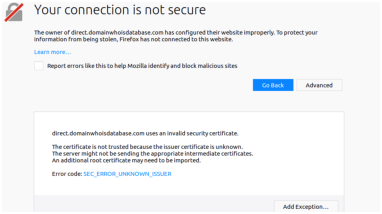
However, as you are using our trusted service, you can safely add an exception by pressing the button on the bottom. Add the exception permanently. Doing these steps you will be able to access the URLs mentioned in the last Section of the present document without the basic http authentication.
Opera can use the certificates managed by the command-line tools available on Linux. To add the certificate, you need to install these tools.
On Debian/Ubuntu/Mint, you should do this by
sudo apt-get install libnss3-tools
while on Fedora and other yum-based systems:
yum install nss-tools
(Please consult the documentation of your distribution if you use a system in another flavor.) The command for adding the certificate is
pk12util -d sql:\$HOME/.pki/nssdb -i pack.p12
This will prompt you for the certificate password. You can list your certificates by
certutil -d sql:\$HOME/.pki/nssdb -L
Now if you open any of the accessible URLs listed at the end of this document, first of all you need to add an exception for the self-signed SSL certificate of the webpage. Then the browser will offer a list of your certificates to decide which one to use with this webpage. Having chosen the just installed certificate, you shall have the secure access to the page, without being prompted for a password.
Currently you can access the following URLs with this method. You shall find the feeds under these base URLs. This means, if you replace “http://domainwhoisdatabase.com” with “https://direct.domainwhoisdatabase.com” in the respective feed names, you shall be able to access all the feeds below the given base url, once you have set up the SSL authentication.
WHOIS data can be downloaded from our ftp servers, too. In case of newer subscribers the ftp access is described on the web page of the subscription.
You can use any software which supports the standard ftp protocol. On most systems there is a command-line ftp client. As a GUI client we recommend FileZilla (https://filezilla-project.org, which is a free, cross-platform solution. Thus it is available for most common OS environments, including Windows, Mac OS X, Linux and BSD variants.
On Windows systems, the default downloads of FileZilla contain adware, thus most virus protection software do not allow to run them. To overcome this issue, download FileZilla from the following URL:
The files downloaded from this location do not contain adware.
For the subscriptions after 2020, the ftp access to the data works with the following settings:
Consult also the information pages of your subscription.
This applies to legacy and quarterly subscriptions, the data can be accessed as described below in case of legacy subscriptions (i.e. those who use bestwhois.org and domainwhoisdatabase.com for web-based access).
As a rule of thumb, if the feed you download has the base URL is
you will find it on the ftp server
while if it is under
you have to connect the ftp server
(please set the port information in your client) to access the data.
If you log in into the server, you will find the data in a subdirectory in your root ftp directory named after the feed. There are some exceptions, which are documented in the description of the given feed in the appropriate manual. You will see only those subdirectories which are accessible within any of your subscription plans there.
A word of caution: as most of the feeds contain a huge amount of data, some ftp operations can be slow. For instance, to obtain the directory listing of some of the feed directories may take a few minutes, so please be patient, do not cancel the operation after a shorter time. (Ftp does not have the feature to show a part of the directory listing or a listing stored in a cache, as in case of the web access.)
If your subscription covers a subset of quarterly releases only, you will find these under quarterly_gtld and quarterly_cctld, in a subdirectory named after the release version.
Our FTP servers use 4 ports: 21, 2021, 2121, and 2200. In order to use our ftp service, you need to ensure that the following ports:
are open on both TCP and UDP on your firewall.
If the respective ports are not open, you will encounter either of the following behaviors: You cannot access the respective server. You can access the respective server, but after login, you can’t even get the directory listing, it runs onto timeout. If you encounter any of these problems, please revise your firewall settings.
This document was translated from LATEX by HEVEA.
